Naturaleza dinámica de las vocales del español rioplatense
The dynamic nature of Rioplatense Spanish vowels
Sofía Romanelli
Universidad Nacional de Mar del Plata
Andrea Menegotto
Universidad Nacional de Mar del Plata - CONICET
Resumen
Los presupuestos habituales en fonética hispánica señalaban que al ser las vocales del español estables, aunque midiéramos los formantes en el 25%, 50% y 75% de la duración, los valores de los hablantes nativos de español no deberían mostrar diferencias significativas, a diferencia de lo que sucede en el inglés, lengua en la que se identificó la existencia de Vowel Inherent Spectral Change (VISC), o cambio espectral inherente de las vocales, es decir, variaciones sistemáticas en los valores de los formantes de las vocales a lo largo de su duración. Sin embargo, en una serie de estudios previos observamos que las vocales / ε ο/ del español rioplatense presentaban cambio espectral tanto en el F1 como en el F2, evidenciando principalmente mayor movimiento espectral en la primera porción de la vocal en relación con la última (Romanelli & Menegotto 2018; Romanelli, Menegotto & Smyth 2018). En este trabajo, evaluamos dos formas diferentes de medir el VISC con datos de dos de esos experimentos y proponemos una nueva medida que permite especificar tanto la magnitud del cambio como su dirección para cada formante por separado y para cada porción vocálica. Al hacerlo, confirmamos que las vocales / ε ο/ del español rioplatense son dinámicas.
palabras clave: vocales; español rioplatense; cambio espectral.
Abstract
Common assumptions in Hispanic phonetics pointed out that as Spanish vowels are stable entities, even if we were to measure formants at the 25%, 50% and 75% of the duration of the vowel, formant frequencies of native Spanish speakers would not show significant differences. Spanish contrasts with English, as English vowels have been shown to evidence Vowel Inherent Spectral Change (VISC), that is, systematic variations in their formant frequencies across the duration of the vowel. However, a series of previous studies have reported that River Plate Spanish vowels / ε ο/ show spectral change both in the first and second formants, evidencing greater spectral change mostly on the first portion of the vowel in comparison to the second one (Romanelli & Menegotto 2018; Romanelli, Menegotto & Smyth 2018). In the present article, we assess two different dynamic acoustic measures to track the formant movement of vowels over time with data from two of those experiments. We also propose a new measure that combines the advantages of these two measures, as it specifies not only the magnitude of spectral change but also the direction of the change for each formant frequency and each vowel portion. In doing so, we confirm that River Plate Spanish vowels / ε ο/ evidence spectral change.
keywords: vowels; River Plate Spanish; spectral change.
1. Estado del arte: ¿las vocales del español son sonidos estables?
1.1 Formantes estables
En los últimos años hemos estado estudiando las propiedades acústicas y perceptuales de las vocales y el acento léxico en posición final de palabra en la interlengua de aprendices de español rioplatense como lengua extranjera (Romanelli & Menegotto 2014, 2018; Romanelli, Menegotto & Smyth 2015a, 2015b, 2018). Nos interesaron particularmente las vocales / ε ο/ en estas condiciones porque distinguen gramaticalmente las desinencias de las 1.as y 3.as personas del singular de la mayoría de los verbos; los contrastes entre / ε ο/ tónicos y átonos afectan a todos los verbos regulares de la primera conjugación exhaustivamente:
- (1) toma-tomá, tome-tomé, tomo-tomó, tomara-tomará, tomare-tomaré
y a todos los regulares de la segunda y la tercera conjugación:
- (2) come-comé; coma-come-como; vivo-vive-viva
Además, como el español es una lengua pro-drop (Zagona 1988) o, desde otra perspectiva, una lengua en la que los pronombres personales nominativos son opcionales (Green 1990:245), se requiere que el hablante produzca y los oyentes interpreten la vocal final del verbo con su correspondiente valor acentual para fijar la forma y la referencia del sujeto. Es decir que los hablantes nativos utilizan las terminaciones verbales más que los pronombres personales como pistas para dar estructura a la oración.
Para nuestros estudios asumíamos, como era habitual hasta entonces, que las vocales del español eran acústicamente estables, es decir que no sufrían cambios significativos en su calidad vocálica ni siquiera en función del acento léxico (Hualde 2014; Quilis & Esgueva 1983). Sin embargo, nuestras investigaciones sobre el español rioplatense nos mostraron que, muy por el contrario, las vocales del español son bastante dinámicas en su estructura interna (Romanelli & Menegotto 2018; Romanelli et al. 2018).
Recordemos algunos conceptos básicos para comprender las consecuencias de esos resultados previos:
Las vocales son los sonidos lingüísticos que universalmente se perciben con mayor facilidad. Se componen de varias ondas armónicas que resuenan simultáneamente y que pueden describirse y medirse con diferentes instrumentos (cualquier buena computadora puede hacerlo con los programas adecuados) de manera aislada. Es decir que cada onda armónica individual, llamada formante (F), tiene su propia caracterización acústica independiente. Así, cada vocal puede describirse como un conjunto de formantes: F0, F1, F2 y F3. Los formantes tienen diferentes frecuencias que se miden originalmente en hercios o hertz.
F0 es la frecuencia fundamental, que varía para cada hablante según la estructura de su aparato fonador dentro de cierto rango posible: las voces más agudas tienen F0 mayor que las voces graves. Los hablantes adultos hombres tienen rangos de F0 de entre 85 a 180 Hz, y las mujeres entre 165 y 255 Hz (Baken 1987:177). El resto de los formantes (F1, F2 y F3) son ondas armónicas —i.e. proporcionales— en relación al valor de F0.
Teóricamente, existe una correspondencia entre el espacio articulatorio y el espacio acústico de cada vocal. La posición más o menos elevada de la mandíbula inferior y la distancia entre la lengua y la parte superior de la cavidad oral determinan la altura de la articulación (vocales altas, medias o bajas) y se corresponde con el valor de F1. La posición de la lengua distingue la articulación anterior y posterior y se corresponde con F2. Cuanto más alta es la vocal, más bajo es el F1 y cuanto más posterior, más bajo es el F2. Las dos vocales altas del español, /ι/ y /υ/, tienen valores de F1 bastante cercanos (ambas son altas) mientras que se distinguen por los valores de F2, vinculados a la anterioridad/posterioridad de la articulación: cuanto más adelantada, más elevada es la frecuencia de F2 y, cuanto más posterior, menor la frecuencia de F2. Consecuentemente, las vocales /ι/ y /υ/ se distinguen entre sí por los valores del segundo formante. Lo mismo sucedería entre /ε/ y /ο/ (ambas son vocales medias, una anterior y otra posterior, respectivamente).
El F1 y F2 son los más importantes para diferenciar una vocal española de otra e identificar las características propias de cada una (García Jurado y Arenas 2005; Hualde 2014; Martínez Celdrán 1995). En otras lenguas, como el inglés por ejemplo, el F3 también juega un papel identificador relevante, ya que sirve para caracterizar las vocales róticas (Hualde 2014:315). Una manera muy habitual de representar estas propiedades es por medio de una carta de formantes, en la que se grafica exclusivamente la relación entre F1 y F2. De esta manera se reduce la caracterización vocálica a los dos formantes que correlacionan sus valores con las propiedades articulatorias de altura y anterioridad-posterioridad. En el eje X se establecen los valores de F1 y en el eje Y, los valores de F2. Esa relación es la que permite graficar el “triángulo vocálico”. En la Figura 1 podemos ver la clásica carta de formantes del español extraída de Quilis y Esgueva (1983) y en la Figura 2, la carta de formantes construida con nuestros datos para las vocales / ε ο/ tónicas y átonas del español rioplatense.
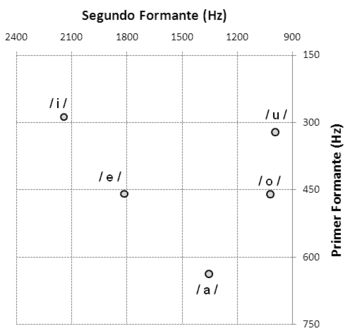
Figura 1. Carta de formantes del español extraída de Quilis y Esgueva (1983:153).
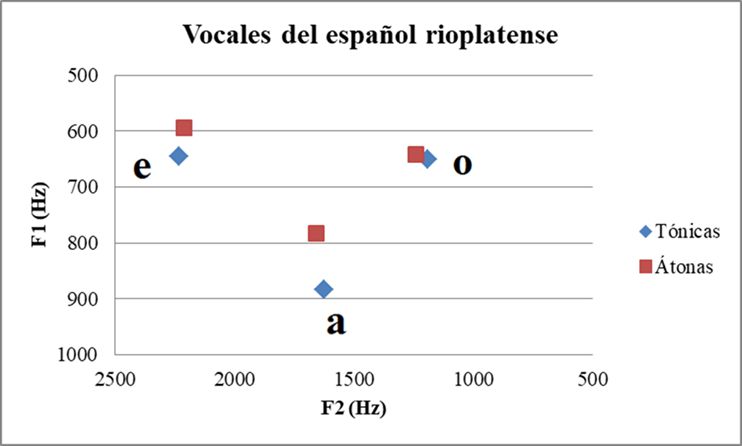
Figura 2. Vocales / ε ο/ tónicas y átonas del español rioplatense en una carta de formantes tradicional, datos extraídos de Romanelli et al. (2018).
La práctica usual siempre había sido analizar los formantes en un único punto que corresponda al núcleo de la vocal (Peterson & Barney 1952). Es decir, se asumía que a lo largo de toda la duración del sonido vocálico las frecuencias serían invariables. Solo habría modificaciones al inicio y al final por razones de coarticulación con el sonido previo y con el sonido posterior. Por ese motivo, se aceptó tradicionalmente que el valor de los formantes se midiera en el 50% de la duración, es decir, la frecuencia en el punto medio de la duración del sonido (Peterson & Barney 1952).
La distinción entre diptongos y monoptongos se derivaba entonces de esta caracterización. Los monoptongos eran definidos como sonidos estables, es decir, sonidos que no mostrarían cambio espectral1, mientras que los diptongos se caracterizaban por ser sonidos espectralmente dinámicos.
1.2 Formantes en movimiento
En 1986, Nearey y Assmann acuñaron el término Vowel Inherent Spectral Change (VISC) (cambio espectral inherente de las vocales) para referirse a las variaciones sistemáticas que se producen en los valores de los formantes de las vocales tensas y laxas del inglés a lo largo de su duración. Este término comenzó a utilizarse para hacer referencia no solo a los cambios en las trayectorias formánticas de los diptongos, sino también a los cambios en el tiempo de las vocales inglesas consideradas monoptongos.
La medición del VISC implica tomar los datos no solo en el 50% de la duración de la vocal, sino también, en, al menos, otros dos puntos más. Los datos más exhaustivos son los de Hillenbrand, Getty, Clark & Wheeler. (1995), quienes midieron las frecuencias vocálicas en diez puntos equidistantes de la duración de las vocales del inglés en un amplio corpus de hablantes nativos (hombres, mujeres y niños), junto con muchos otros autores que fueron sumando datos (Assman & Katz 2000; Elvin, Williams & Escudero 2016; Fox & Jacewicz 2009; Jacewicz, Fox & Salmons 2011a, 2011b). De esta manera, se fue debilitando la certeza de que los monoptongos del inglés fueran sonidos estables sin cambio espectral. El movimiento de formantes era evidente.
Representar el cambio espectral en una carta de formantes permitió ver que el movimiento tenía una cierta dirección: lo que antes se representaba como un único punto en la intersección de F1 y F2, ahora es una serie de puntos de intersección que caracterizan cada vocal a lo largo de su duración y que muestra, entonces, una dirección determinada.
Esperábamos, entonces, para nuestras investigaciones, que los aprendices de español con inglés L1 mostraran mayor VISC que los controles nativos de español L1, y que a medida que aumentara la competencia del aprendiz en la L2, disminuyera el VISC. Los presupuestos iniciales eran que, al ser las vocales del español estables, aunque midiéramos los formantes en el 25%, el 50% y el 75% de la duración, los valores de los hablantes nativos de español no debían mostrar diferencias significativas.
Grande fue nuestra sorpresa al descubrir que incluso los hablantes nativos de español mostraban movimientos significativos, como se observa en la carta de formantes de los datos reportados en Romanelli et al. (2018) (Figura 3) (ver sección 3.1. para una detallada caracterización dinámica de dichas vocales).
1.3. El presente trabajo
En este trabajo continuamos verificando –recurriendo a diversos métodos de cálculo– que las vocales / ε ο/ del español rioplatense en posición final de palabra presentan cambio espectral inherente, tanto en posición tónica como átona y en diferentes estilos. Evaluamos dos formas de medir el VISC con datos de dos experimentos previos y proponemos una tercera fórmula que reúne las ventajas de las dos mediciones anteriores, ya que permite especificar tanto la magnitud del cambio como su dirección para cada formante por separado y para cada porción vocálica (primera vs. última). De esta manera, seguimos confirmando que las vocales del español son dinámicas tanto en el F1 como en el F2, evidenciando principalmente mayor movimiento espectral en la porción inicial de la vocal (del 25% al 50% de su duración) en relación con la porción final (del 50% al 75).
2. Metodología
2.1 Participantes
Diez hablantes nativos femeninos de español rioplatense (rango etario=19-33, M=28.4) participaron en dos experimentos diferentes. Las participantes eran estudiantes avanzadas o graduadas de la Universidad Nacional de Mar del Plata (UNMdP) nacidas en la ciudad de Mar del Plata, Buenos Aires, Argentina. En lo que respecta al conocimiento de otras lenguas, dos participantes tenían un nivel de dominio avanzado de inglés, y otras tres, un nivel intermedio de la misma L2; las cinco participantes restantes no reportaron conocimiento de ninguna L2. Ninguna reportó problemas en el habla o la audición en el cuestionario que completaron luego de la sesión de grabación.
Como las participantes de este estudio eran hablantes femeninas únicamente, no fue necesario normalizar los valores formánticos de las vocales para reducir las diferencias fisiológicas entre hombres y mujeres.
2.2 Materiales
En ambos experimentos, las hablantes nativas de español produjeron 54 vocales en sílaba tónica y átona ubicadas al final de palabras reales, como por ejemplo astuta, tupé, y busco. En el Cuadro 1 se muestran más detalles sobre el tipo y la cantidad de palabras elicitadas por vocal y contexto prosódico. Las palabras aparecieron en dos contextos diferentes: aisladas en una lista de palabras y en oraciones dentro de un texto. Las vocales estaban precedidas por las consonantes oclusivas sordas / κ/ para minimizar los efectos de la coarticulación. Para más detalles sobre los textos y las palabras utilizadas, consultar Romanelli et al. (2018) y Romanelli & Menegotto (2018).
| a |
e |
o |
| Tónica |
Átona |
Tónica |
Átona |
Tónica |
Átona |
| buscá (x3) |
astuta (x2) |
busqué (x2) |
fuerte (x3) |
acercó |
campo (x3) |
| despertá (x2) |
cerca (x3) |
esté (x2) |
inteligente |
acostó |
canto (x2) |
| está |
cierta |
tupé (x2) |
parque |
cantó |
pronto |
| kipá (x2) |
Europa (x2) |
|
torpe (x3) |
despertó |
tronco (x4) |
|
|
|
que (x4)
| replicó (x2) |
|
|
|
|
|
saltó (x2)
| |
|
|
|
|
trepó (x2) |
|
Cuadro 1. Palabras elicitadas por vocal y contexto prosódico.
2.3 Procedimiento
Las participantes realizaron dos tareas: la lectura de (a) una adaptación de la fábula de Esopo “El gallo, el oso y la pantera” y (b) una lista de palabras. El objetivo del experimento 1 era evaluar el efecto del acento léxico sobre la calidad de las vocales / ε ο/ del español, independientemente del contexto en el que aparecieran y de la consonante previa, con lo cual se colapsaron los dos contextos y las tres consonantes en el análisis estadístico.
El propósito del experimento 2, sin embargo, era explorar la interacción entre el acento léxico y el estilo de habla, es decir, observar si tanto las vocales tónicas como las átonas se hiperarticulan y son más dinámicas en el habla cuidada en comparación con un estilo menos cuidado, y si este efecto se evidencia en los tres contextos consonánticos / κ/. La lectura de la lista de palabras se consideró representativa de un estilo de habla cuidada, y la lectura de la fábula, representativa de un estilo de habla más fluida.2
Se grabó a los participantes individualmente en un aula silenciosa frente al investigador, quien, a su vez, estaba sentado frente al monitor de una computadora. Los participantes estaban conectados a un micrófono vincha Pure Audio NC-1 85VM USB PC (Andrea Electronics) conectado a una computadora portátil Dell. Las grabaciones se realizaron con el software de audio Andrea Electronics AudioCommander.
2.4. Análisis de los datos: cómo se mide el VISC
La caracterización de la trayectoria formántica (tanto F1 como F2) de las vocales tónicas y átonas / ε ο/ del español rioplatense producidas por hablantes nativos femeninos se obtuvo por medio de mediciones acústicas realizadas en tres puntos equidistantes de la vocal (P1, P2 y P3) correspondientes al 25, 50 y 75% de la duración de la misma. Como en otras investigaciones, se descartó el segmento inicial (0% al 25% de la duración de la vocal) y el final (75% al 100% de la duración de la vocal) (Schwartz, Kaźmierski, Weckwerth, Jekiel & Malarski 2018; Williams & Escudero 2014) para minimizar el efecto de coarticulación de las consonantes vecinas sobre las trayectorias de los formantes.
Todas las medidas acústicas se realizaron por medio del programa Praat (Boersma y Weenink 2014). El inicio y el final de la vocal se identificaron manualmente por medio de la forma de onda y el espectrograma sincronizados. El comienzo de la vocal se midió desde el comienzo de la periodicidad luego de la explosión de la consonante oclusiva y el final, en el punto donde la amplitud disminuyó significativamente (Fox y Jacewicz 2009; Jacewicz et al. 2011a). En los casos en los cuales la vocal final estaba seguida de una palabra que comenzaba con vocal, se localizó el final de la vocal en el punto en el espectrograma en donde el primer formante de la segunda vocal ascendía. Los valores de F1 y F2 se extrajeron automáticamente por medio de un script de Praat en tres puntos equidistantes de las vocales (Lennes 2003).
Se calculó el VISC de tres maneras diferentes:
- 1.Experimento 1. Comparación de los valores de los formantes en los tres puntos temporales de la vocal
Se compararon los valores del F1 y el F2 (en hertz) extraídos en los tres puntos temporales de la vocal entre sí (25% vs. 50%, 25% vs. 75%, y 50% vs. 75%) para cada segmento vocálico. Es decir, se comparó P1 vs. P2, P1 vs. P3, y P2 vs. P3. En la sección de resultados 3.1 no reportaremos el cambio de P1 vs. P3 ya que consideramos que la información más importante respecto al cambio espectral es la que se observa en P1 vs. P2 y en P2 vs. P3.
Este método es muy simple y muestra claramente en qué parte de la vocal, es decir, en qué punto temporal de la vocal se observa el cambio y en qué dirección. Esta comparación, sin embargo, no muestra la magnitud del cambio entre las mediciones acústicas.
- 2. Experimento 2. Valor único de cambio espectral (λ)
Esta forma de cálculo muestra solamente la magnitud total del cambio espectral, colapsando el F1 y el F2 del 75% al 25% de la vocal en un único valor convertido a barks, utilizando la fórmula de Traunmüller (1990). Los valores en hercios (Hz) se convirtieron a barks para normalizar los valores del F1 y el F2 (Ferguson y Kewley-Port 2007; Kewley-Port y Zheng 1999; Leung et al. 2016). El bark es “una unidad de frecuencia perceptiva, que relaciona en bandas escalares la frecuencia absoluta (en Hz) con las frecuencias medidas perceptivamente. Usando el bark, un sonido en el dominio de la frecuencia puede ser convertido a sonido en el dominio psicoacústico” (Martínez Celdrán & Fernández Planas 2007:29).
El valor único de cambio espectral (λ) compara la información de P3 (los formantes al 75% de la vocal) en relación con la información de P1 (Ferguson & Kewley-Port 2007; Leung, Jongman, Wang & Sereno 2016). El promedio de F1 y F2 de cada vocal en cada una de las condiciones se convirtió a barks. El cambio espectral corresponde a la suma en barks del cambio en la frecuencia de formantes absoluta del F1 y el F2 para cada vocal (Leung et al. 2016). La fórmula es la siguiente:
- λ= |F175 - F125| + |F275 - F225|
- F175, F125, F275, y F225 son los valores del F1 y F2 en barks obtenidos al 75% y 25% de la duración de la vocal. Un mayor movimiento espectral se asocia a un mayor valor de λ.
- 3. Valores de cambio espectral por porción vocálica y por formantes individuales
Se propone en este artículo una nueva manera de medir el cambio espectral que capte no solo la magnitud del cambio, sino también la dirección del mismo para cada formante por separado, reanalizando los datos del experimento 1 con este nuevo método de cálculo. Los valores del F1 y F2 para cada vocal en los tres puntos equidistantes de la duración vocálica (P1: 25%, P2: 50% y P3: 75%) se transformaron a barks. Luego se calculó el cambio espectral en dos porciones vocálicas, la porción inicial P2-P1 (50%-25%) y la porción final P3-P2 (75%-50%) para poder compararlas utilizando las siguientes fórmulas:
- F1 (P2-P1) = (F150 – F125)
- F1 (P3-P2) = (F175 – F150)
- F2 (P2-P1) = (F250 – F225)
- F2 (P3-P2) = (F275 – F250)
3. Resultados
3.1 Experimento 1: Valores por formante en tres puntos temporales
La Figura 3 muestra las trayectorias del F1 y el F2 de las vocales del español rioplatense del experimento 1.
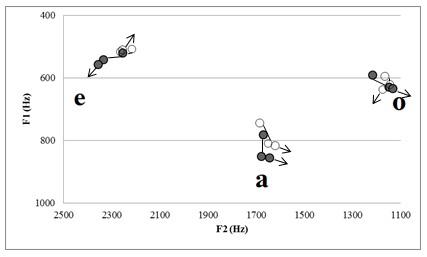
Figura 3. Vocales tónicas (en gris) y átonas (en blanco) del español rioplatense producidas por diez hablantes nativos femeninos.
3.1.1 F1 y F2 de /a/
Se realizó un ANOVA3 con los valores del F1 de la vocal /a/ y se observó un efecto principal significativo de los factores Posición (P1, P2 y P3), F(2,18)=24,365, p=,001, y Acento Léxico, F(1,9)=44,411, p=,001, mientras que la interacción Posición x Acento no resultó significativa. El F1 de /a/ aumentó significativamente de P1 (764 Hz) a P2 (830 Hz) (25% vs. 50%) (p=,001), pero se mantuvo estable de P2 a P3 (836 Hz) (50% vs. 75%) (p=1,000). En cuanto al acento léxico, el F1 de la /a/ tónica (829 Hz) fue más alto que el F1 de la /a/ átona (790 Hz).
En lo que respecta al F2, el análisis estadístico mostró un efecto significativo del factor Posición, F(2,18)=6,691, p=,007, mientras que el efecto de Acento Léxico y la interacción entre estos dos factores no fueron significativas. Los resultados muestran una disminución del F2 de P2 (1664 Hz) a P3 (1633 Hz) (p=,002) (se retrajo la lengua), mientras que no hubo cambios significativos en el F2 de P1 (1678 Hz) a P2 (p=1,000).
3.1.2 F1 y F2 de /ε/
El ANOVA con los valores del F1 de /ε/ mostró efectos principales de los factores Posición, F(2,18)=6,291, p=,008, y Acento léxico, F(1,9)=13,487, p=,005, y una interacción significativa Posición x Acento, F(2,18)=12,631, p=,001. Se exploró la interacción Posición x Acento mediante dos ANOVAS comparando las posiciones entre sí en cada condición de acento. Para la /ε/ tónica, se observó un efecto de Posición, F(2,18)=11,449, p=,001, mostrando un aumento significativo del F1 de P1 (520 Hz) a P2 (542 Hz) (p=,017), mientras que no hubo diferencias entre P2 y P3 (557 Hz) (p=,146). Para la /ε/ átona, no se observaron diferencias en el F1 entre los puntos temporales, F(2,18)=1,089, p=,358.
En cuanto al F2, se observó un efecto principal de Posición, F(2,18)=24,298, p=,001, y Acento, F(1,9)=18,047, p=,002, mientras que la interacción entre estos dos factores no fue significativa. Se compararon los valores del F2 en las tres posiciones entre sí (colapsando ambas condiciones de acento), y se observó un aumento del F2 de P1 (2236 Hz) a P2 (2300 Hz) (p=,001) (avanzó la lengua), mientras que no se observaron diferencias significativas de P2 a P3 (2306 Hz) (p=1,000). El efecto de Acento mostró que el F2 de la /ε/ tónica (2316 Hz) fue significativamente más alto que el de la /ε/ átona (2246 Hz).
3.1.3 F1 y F2 de /ο/
Para el F1 de /ο/, el ANOVA evidenció un efecto principal significativo del factor Posición únicamente, F(2,18)=22,706, p=,001, mientras que no se registró un efecto significativo de Acento Léxico ni tampoco de la interacción Posición x Acento. Hubo diferencias significativas en el F1 en función de la posición: el F1 aumentó significativamente de P1 (593 Hz) a P2 (625 Hz) (p=,005) y de P2 a P3 (635 Hz) (p=,012).
Por último, en lo que respecta al F2 de /ο/, el ANOVA mostró un efecto significativo de Posición, F(2,18)=6,456, p=008, pero no de Acento léxico, mientras que la interacción Posición x Acento léxico fue significativa, F(2,18)=17,252, p=,001. Se analizó la interacción comparando las posiciones temporales entre sí en cada una de las condiciones de acento léxico. Se observaron diferencias entre las posiciones para el F2 de la /ο/ tónica, F(2,18)=20,745, p=,001. El F2 de /ο/ disminuyó significativamente de P1(1216 Hz) a P2 (1148 Hz) (p=,001) (se retrajo la lengua) mientras que se mantuvo estable de P2 a P3 (1132 Hz) (p=,502). En el caso de la /ο/ átona, no se registraron diferencias significativas en el F2 entre ninguna de las tres posiciones.
3.2 Experimento 2: Único valor de cambio espectral (λ)
Para el cambio espectral de la vocal /a/ (Figura 4), se observó una interacción significativa de Estilo de Habla x Consonante. Para explorar esta interacción, se comparó el cambio espectral en el estilo de habla cuidada con el estilo fluido en cada uno de los tres contextos consonánticos. Estos análisis mostraron que hubo mayor cambio espectral en el habla cuidada en comparación con el habla fluida en contexto dental (1,35 bark vs. ,84 bark) y velar (1,17 bark vs. ,63 bark).
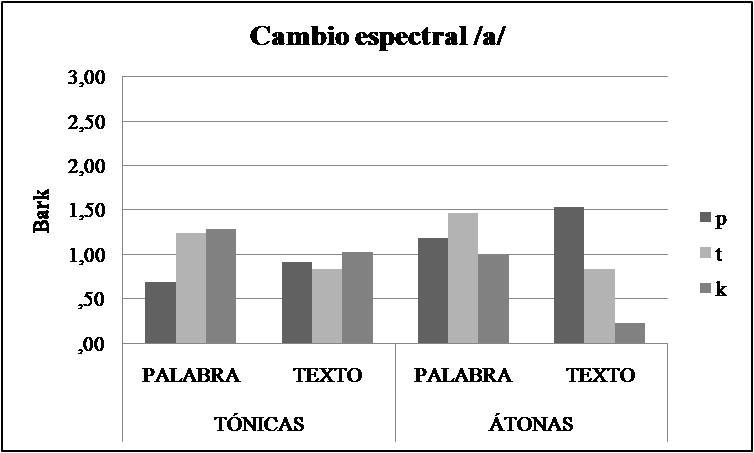
Figura 4. Cambio espectral de la /a/ tónica y átona del español rioplatense en función del estilo de habla y del contexto consonántico.
En cuanto al cambio espectral en /ε/ (Figura 5), los resultados indicaron que, contrariamente a lo esperado, el cambio espectral en la vocal /ε/ fue mayor en el habla fluida (1,04 bark) que en el habla cuidada (,81 bark).
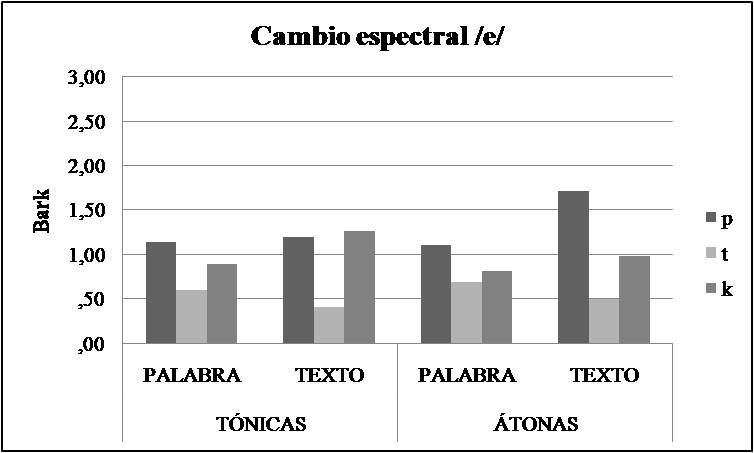
Figura 5. Cambio espectral de la /ε/ tónica y átona del español rioplatense en función del estilo de habla y del contexto consonántico.
Por último, el análisis de cambio espectral para la vocal /ο/ reveló un efecto marginalmente significativo de Estilo de Habla, indicando mayor cambio espectral para /ο/ en estilo de habla cuidada (1,40 bark) en comparación con el habla fluida (1,00 bark) (Figura 6). Los resultados mostraron además que en contexto bilabial, hubo mayor cambio espectral en el habla fluida (1,31 bark) que en el habla cuidada (,95 bark), contrariamente a lo que se predijo. En contexto dental, sin embargo, el mayor cambio espectral se registró en el habla cuidada (2,07 bark) en comparación con el habla fluida (,88 bark). Por otro lado, se observaron diferencias entre el estilo de habla en función del contexto prosódico: hubo mayor cambio espectral en el habla cuidada (1,61 bark) en relación con el habla fluida (,86 bark) solo en las vocales tónicas.
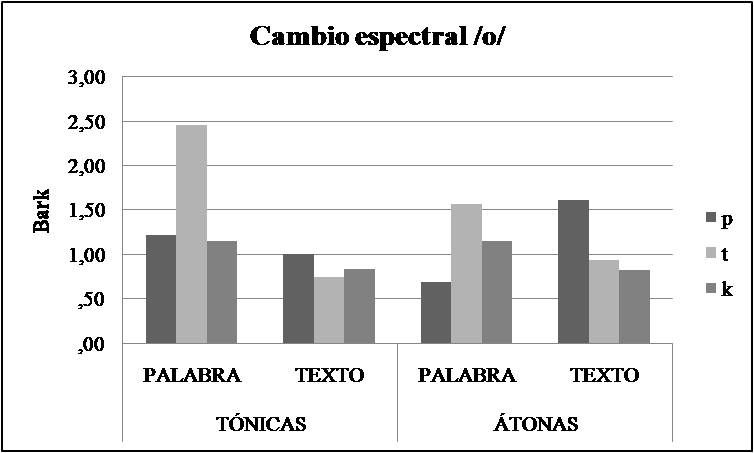
Figura 6. Cambio espectral de la /ο/ tónica y átona del español rioplatense en función del estilo de habla y del contexto consonántico.
3.3 Valores de cambio espectral por porción vocálica y por formante
Se realizaron seis ANOVAs, una para cada vocal con F1 y F2 por separado, con los factores Porción (Porción 1= P2-P1 vs. Porción 2= P3-P2) y Acento Léxico (tónica vs. átona) como factores intrasujetos, es decir que se comparó el cambio espectral en las dos porciones vocálicas en cada condición de acento léxico.
3.3.1 F1 y F2 de /a/
El ANOVA para el F1 de /a/ reveló un efecto principal significativo del factor Porción, F(1,9)=196,972, p=,001, mientras que el factor Acento y la interacción Porción x Acento no resultaron significativas. Este resultado indica que si bien el F1 aumentó en ambas porciones vocálicas, el mayor cambio espectral se observó en la primera parte de la vocal (,459 bark) en comparación con su final (,022 bark), independientemente del acento léxico (Figura 7).
En cuanto al F2, ningún factor o interacción fue significativo. Es decir que no hubo cambio espectral significativo ni en la porción inicial (-,094 bark) ni en la final (-,122 bark) en el F2 de /a/. Los resultados muestran además que si bien el cambio espectral en el F2 es similar en ambas porciones de la vocal, el F2 disminuyó.
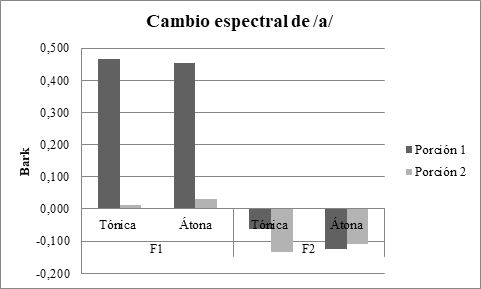
Figura 7. Cambio espectral del F1 y el F2 en la primera y la segunda porción de /a/.
3.3.2 F1 y F2 de /ε/
El ANOVA que se realizó con los valores del F1 para la vocal /ε/ evidenció un efecto principal significativo de los factores Porción, F(1,9)=5,783, p=,040; y Acento, F(1,9)=17,774, p=,002. La interacción Porción x Acento no fue significativa. Se observó un aumento significativo del F1 en el inicio de la vocal (,124 bark) en relación con su final (,033 bark). Además, las vocales tónicas (,150 bark) mostraron mayor cambio espectral en el F1 que las átonas (,007 bark) (Figura 8).
Para el F2, se registró un efecto principal significativo de Porción únicamente, F(1,9)=16,384, p=,003. El F2 de /ε/ aumentó significativamente en el inicio de la vocal (,196 bark) (articulación más anterior), en relación con el cambio espectral registrado en el final de la vocal (,002 bark), el cual se mantuvo estable.

Figura 8. Cambio espectral del F1 y el F2 en la primera y la segunda porción de /ε/.
3.3.3 F1 y F2 de /ο/
Finalmente, en el caso del F1 de la vocal /ο/, el ANOVA evidenció un efecto significativo del factor Porción, F(1,9)=10,558, p=,010, mientras que el factor Acento y la interacción entre estos dos factores no fue significativa. La porción inicial de /ο/ (,245 bark) mostró un aumento significativo del F1 en comparación con su final (,075 bark) (Figura 9). No se observaron diferencias en función del acento léxico.
En el caso del F2 de /ο/, el ANOVA reveló un efecto principal significativo de los factores Porción, F(1,9)=12,588, p=,006, y Acento, F(1,9)=21,353, p=,001, mientras que la interacción Porción x Acento no resultó significativa. Nuevamente, como para el F1 y el F2 de las otras vocales, el mayor cambio espectral se observó en el inicio de la vocal (-,178) en comparación con el final (,028 bark); en este caso, el F2 disminuyó, mostrando un desplazamiento posterior de la lengua. En cuanto al acento léxico, el F2 de la /ο/ tónica (-,224 bark) mostró un mayor cambio espectral que su contraparte átona (,074 bark), y en la dirección contraria.

Figura 9. Cambio espectral del F1 y el F2 en la primera y la segunda porción de /ο/.
4. Discusión
Se emplearon tres formas diferentes de medir los cambios en la trayectoria de los formantes de las vocales del español rioplatense: (1) comparación de los valores de los formantes medidos en tres puntos temporales equidistantes de la vocal: P1, P2 y P3 (experimento 1); (2) valor único de cambio espectral combinando los valores del F1 y F2 en dos puntos temporales de la vocal: P1: 25% y P3: 75% (experimento 2); (3) comparación de los valores de cambio espectral para cada formante por separado en dos porciones vocálicas (P2-P1 vs P3-P2 o porción inicial vs porción final). Contrariamente a las descripciones tradicionales de las vocales del español como entidades estables (Hualde 2014; Quilis y Esgueva 1983), nuestros datos evidencian que las vocales /a/, /ε/ y /ο/ del español rioplatense tienen movimiento espectral. En nuestro conocimiento, no existen hasta el momento otros estudios acústicos que caractericen el movimiento espectral de las vocales del español en ninguna variedad dialectal, con lo cual resulta imposible comparar nuestros resultados con los de otras investigaciones. Si bien los tres métodos empleados en nuestros trabajos coinciden en demostrar que las tres vocales del español estudiadas aquí son dinámicas, difieren en la información que arrojan sobre las características del dinamismo espectral de cada una. A continuación evaluamos las tres maneras de medir el cambio espectral.
4.1 Experimento 1: Valores por formante en tres puntos temporales
El primer método muestra de una manera muy simple y clara en qué formante y punto temporal de la vocal se produce el cambio y en qué dirección. Estos resultados son fáciles de representar e interpretar desde una carta de formantes con múltiples puntos temporales. Con este método se registra claramente que tanto el F1 como el F2 de las vocales / ε ο/ muestran movimiento, principalmente al comienzo de la vocal, mientras que estas evidencian formantes relativamente estables en su porción final. El F1 aumenta para las tres vocales y el F2 aumenta para /ε/ pero disminuye para /ο/ conforme al desplazamiento de la lengua en la articulación de cada vocal, anterior para la vocal /ε/ y posterior para la vocal /ο/. Es decir que, con este método, confirmamos nuestros resultados previos: las vocales / ε ο/ del español rioplatense son sonidos dinámicos y no estables como se presuponía hasta ahora. Es interesante mencionar que encontramos dos fenómenos en nuestros datos que no podemos explicar ni comparar con otros estudios, ya que las investigaciones realizadas sobre las vocales del español no realizan mediciones en múltiples puntos de la vocal (Nadeu 2014; Torreira & Ernestus 2011). Por un lado, observamos que el F1 de /ο/ también aumentó en la porción final de la vocal y, por el otro lado, que el F2 de /a/ disminuyó también en esta porción vocálica.
La principal ventaja de este método de análisis es que es fácilmente representable por medio de una carta de formantes, de manera tal que es posible graficar todos los sonidos y comparar la dirección del movimiento de todas las vocales simultáneamente. Este análisis tiene, entonces, una importante utilidad para la comparación y análisis de los sistemas fonológicos.
4.2 Experimento 2: Único valor de cambio espectral (λ)
La segunda medida capta únicamente la magnitud total del cambio espectral colapsando el F1 y el F2. Considerando solo dos puntos temporales de la vocal (25% y 75%), esta medida indica con un único valor qué vocal es más dinámica. Un valor de 0 indicaría que no hay dinamismo, por lo que era esperable que las vocales del español mostraran valores cercanos a 0. No es esto lo que encontramos.
Esta medida se ha utilizado para demostrar que las vocales producidas en un estilo de habla cuidado evidencian mayor cambio espectral que las producidas en un estilo de habla fluida, como es el caso de las vocales / ο/ del español rioplatense (Romanelli & Menegotto 2018) y de los pares de vocales tensas y laxas del inglés (/ι-I/, /A-ς/, /υ-Y/) (Leung et al. 2016). Además, Leung et al. (2016) emplearon este cálculo para mostrar que las vocales laxas son más dinámicas que las tensas. Sin embargo, al ser una medida global, no permite recuperar la información referente al cambio registrado en cada uno de los formantes. No solo no es posible precisar en qué formante se produjo el mayor movimiento espectral, sino que tampoco se puede especificar la dirección del cambio.
Obviamente, el cambio espectral medido en estos términos no puede visualizarse y representarse en una carta de formantes, sino que hay que recurrir, por ejemplo, a un gráfico de barras. Las diferencias en los valores hace bastante fácil comparar de manera global y con un único índice qué sonido es más dinámico siempre y cuando no haya cambio de dirección en el movimiento.
Por último, es importante mencionar que otra desventaja de este método es que al incluir en su cálculo los valores formánticos de solo dos puntos temporales de la vocal (25% y 75%), oculta información sobre la caracterización de trayectorias formánticas más complejas en las que hay cambio de dirección del movimiento, como las que muestran una forma curva, subestimando así la magnitud del cambio espectral (Fox & Jacewicz 2009). Las medidas que emplean múltiples puntos temporales son las que mejor describen el dinamismo de los formantes vocálicos.
4.3 Valores de cambio espectral por porción vocálica y por formante
De manera similar a la primera medida de cambio espectral (cálculo por formante en tres puntos temporales), la medida que se propone en este artículo considera tres puntos temporales de la vocal. Ambas medidas captan, entonces, la dirección del cambio espectral, pero además nuestra propuesta se diferencia del primer cálculo en cuanto además calcula la magnitud del cambio para cada porción de la vocal.
Es interesante evaluar si los resultados que arrojan ambos métodos para el experimento 1 son similares. Comenzando con el F1, ambas medidas parecen coincidir en que el mayor movimiento espectral para las tres vocales / ε ο/ se observa al comienzo de la vocal (del 25% al 50%), mostrando, sin embargo, estabilidad en la porción final de la vocal, excepto en el caso de la /ο/, la cual muestra movimiento espectral también en la porción final al emplear la primera medida pero no la tercera. El cambio en la primera porción vocálica se refleja siempre en un aumento del F1. En el caso de /a/, mientras que la primera medida muestra que la /a/ tónica se produce con un F1 más alto que la átona, el análisis con los valores de la tercera medida no reporta esta diferencia como estadísticamente significativa, aunque los valores numéricos indicarían que hay mayor movimiento espectral, caracterizado por un aumento del F1, también en las vocales tónicas. En el caso de /ε/, la primera medida muestra una interacción Posición x Acento significativa, evidenciando cambios en el F1 de la primera porción de las vocales tónicas únicamente. De manera similar, aunque no exactamente igual, la tercera medida muestra mayor cambio espectral en la primera porción de /ε/, independientemente del acento léxico, y evidencia mayor cambio espectral en el F1 de la /ε/ tónica en comparación con su contraparte átona.
En lo que respecta al F2, el primer método muestra una disminución del F2 para la vocal /a/ en la porción final de la vocal, mientras que el tercer método no capte ninguna diferencia significativa entre la magnitud del cambio de la porción inicial (-,094 bark) y la porción final (-,122 bark), aunque numéricamente el mayor cambio espectral se observa en la última porción también. En el caso de /ε/, observamos que si bien la tercera medida no evidencia una diferencia significativa de cambio espectral entre el F2 de la /ε/ tónica y átona, como lo hace la primera medida, la media de los valores de cambio espectral para las vocales tónicas (,152 bark) es mayor que para las átonas (,046 bark). Por último, con respecto a la vocal /ο/, mientras que el análisis estadístico de la primera medida arrojó una interacción significativa entre los factores Acento y Posición, es decir, diferencias en el movimiento del F2 en función de la condición de acento léxico, la interacción Acento x Porción no resultó significativa en la tercera medida, aunque sí lo fueron los factores Porción y Acento léxico, evidenciando mayor cambio espectral en el F2 en la porción inicial, independientemente del acento léxico, y un mayor cambio espectral en las tónicas con respecto a las átonas, independientemente de la porción vocálica. En resumen, podríamos decir que si bien los análisis estadísticos resultantes de la aplicación de ambas medidas no arrojan exactamente los mismos resultados, caracterizan de manera relativamente similar y efectiva las trayectorias dinámicas de las vocales del español rioplatense.
Es de suma relevancia destacar que tanto con el primero como con el tercer método es posible hacer predicciones respecto a las dificultades que presentarán los hablantes no nativos de español al adquirir los sonidos de esta lengua. Por ejemplo, en Romanelli et al. (2018) se compararon las trayectorias de los formantes de las vocales del español producidas por hablantes nativos de español y por hablantes nativos de inglés que aprenden español como L2, y se registraron diferencias entre los grupos. Se observó que mientras los hablantes nativos no mostraban un cambio espectral significativo en el F1 en el inicio de las vocales /ε ο/, los hablantes nativos de inglés evidenciaban una disminución significativa del F1 en el tramo final, debido a que estas vocales se diptongan en su lengua materna. Con la identificación de las diferencias en las trayectorias vocálicas de la L1 y la L2, es posible ayudar a los hablantes no nativos en la adquisición de los sonidos de la L2 mediante la implementación de un entrenamiento focalizado.
En la actualidad estamos evaluando otras medidas de cambio espectral reportadas en la bibliografía existente, como por ejemplo el ángulo espectral (spectral change, Ferguson & Kewley-Port 2007; Jin & Liu 2013; Leung et al. 2016), la distancia del VISC (distance of VISC, Jin & Liu 2013) y una adaptación de la pendiente del formante (formant slope, Schwartz 2018; Schwartz, Aperliński, Kaźmierski & Weckwerth 2016) para analizar cuál o cuáles son las que mejor describen las trayectorias de los formantes vocálicos del español.
5. Conclusión
Exploramos las trayectorias de los formantes de las vocales españolas por medio de dos formas diferentes de medir el VISC y propusimos una nueva medida que reúne algunas de las ventajas de las dos mediciones previas, puesto que permite especificar tanto la magnitud del cambio como su dirección para cada formante por separado y para cada porción vocálica. En líneas generales, los resultados arrojados por la primera y la tercera medida son similares y confirman que las vocales del español rioplatense son dinámicas tanto en el F1 como en el F2, evidenciando principalmente mayor movimiento espectral en la primera porción de la vocal en relación con la última.
Nuestros resultados nos permiten relativizar algunas afirmaciones tradicionales respecto de la caracterización de las vocales del español como acústicamente estables y exigen una reflexión más profunda sobre la conceptualización acústica y fonológica de los diptongos frente a los monoptongos. Si bien comparativamente con otras lenguas como el inglés las vocales del español rioplatense parecen, efectivamente, ser más estables, existen cambios espectrales evidentes que las nuevas tecnologías disponibles nos permiten detectar y analizar.
Resaltamos además la utilidad de realizar mediciones acústicas en varios puntos de la vocal para caracterizar con mayor precisión no solo las trayectorias dinámicas de las vocales del español como L1, sino también las del español como L2. De esta forma, se podrán comparar ambas trayectorias vocálicas e identificar de forma más precisa y objetiva las potenciales dificultades que presentarán los hablantes no nativos de español al adquirir los sonidos de esta L2. Por último, creemos que es necesario llevar adelante muchas otras investigaciones que permitan identificar si los cambios espectrales que identificamos en las vocales del español rioplatense son generalizables a todos los contextos o si existen diferentes restricciones fonéticas o fonológicas.
Agradecimientos
El presente artículo se generó en el marco del proyecto PAE 37155 PICT 1889 (2009-2014), “Modelos teóricos para la enseñanza de ELSE”, dirigido por Andrea Menegotto y subvencionado por la Agencia Nacional de Promoción Científica y Tecnológica (ANPCyT), y por tres becas otorgadas a Sofía Romanelli por ANPCyT (2010-2013) y el Consejo Nacional de Investigaciones Científicas y Técnicas (CONICET) (2013-2015; 2016-2018). También le agradecemos a Ron Smyth por sus comentarios sobre versiones anteriores de este manuscrito.
Notas
- Utilizamos indistintamente las expresiones VISC, cambio espectral, dinamismo espectral y cambio en los valores formánticos para referirnos al fenómeno de la variación de la frecuencia de los formantes a lo largo de la duración del sonido.
- Siguiendo la metodología laboviana tradicional para obtener muestras de habla con diferentes estilos (Labov 1966, 1972) y la bibliografía experimental más actual (Ferguson & Kewley-Port 2002, 2007; Ferguson & Quené 2014; Leung et al. 2016; Strange et al. 2007), la lectura de una lista de palabras aisladas comparada con la lectura de textos evidencian puntos diferentes del continuo de atención al habla y formalidad: la lectura de palabras aisladas es un estilo en el que el hablante presta más atención al habla, con lo cual puede considerarse un ejemplo de habla cuidada. La bibliografía experimental considera que la lectura de textos es representativa de “habla conversacional”, lo que es claramente objetable ya que en realidad no hay una conversación. Por tal motivo, hemos optado en este trabajo por las expresiones “habla fluida”, “lectura de texto” o “texto”. Lo importante es que el contraste entre la lectura de palabras aisladas y la lectura de texto permite contrastar dos características prosódicas centrales que diferencian los distintos grados de atención al habla: en el habla con mayor atención al discurso (i.e. en el habla más “cuidada”) las vocales se hiperarticulan, es decir que los gestos articulatorios son más extremos y su duración es mayor (De Jong, Beckman y Edwards 1993; Ferguson & Kewley-Port 2007; Smiljanić & Bradlow 2009) en comparación con las vocales del habla más fluida.
- Un análisis de varianza (ANOVA) prueba la hipótesis de que las medias de dos o más poblaciones son iguales. Esta prueba paramétrica de comparación analiza la dispersión, diferencia de medias y tamaño muestral.
Referencias
Assman, P. & W. Katz. 2000. “Time-varying spectral change in vowels of children and adults”, en: Journal of the Acoustical Society of America 108. 1856-1866.
Baken, R. J. 1987. Clinical Measurement of Speech and Voice. London: Taylor and Francis Lth.
Boersma, P. & D. Weenink. 2014. “Praat: doing phonetics by computer (version 5.4.)”. Programa de computación, http:/a/www.praat.org/.
De Jong, K., M. E. Beckman & J. Edwards. 1993. “The interplay between prosodic structure and coarticulation”, en: Language and Speech 36(2–3). 197–212.
Elvin, J., D. Williams & P. Escudero. 2016. “Dynamic acoustic properties of monophthongs and diphthongs in Western Sydney Australian English”, en: Journal of the Acoustical Society of America 140(1). 576-581.
Ferguson, S. H. & D. Kewley-Port. 2002. “Vowel intelligibility in clear and conversational speech for normal-hearing and hearing-impaired listeners”, en: Journal of the Acoustical Society of America 112. 259–271.
Ferguson, S. H. & D. Kewley-Port. 2007. “Talker differences in clear and conversational speech: Acoustic characteristics of vowels”, en: Journal of Speech, Language and Hearing Research 50. 1241–1255.
Ferguson, S. H. & H. Quené. 2014. “Acoustic correlates of vowel intelligibility in clear and conversational speech for young normal-hearing and elderly hearing-impaired listeners”, en: Journal of the Acoustical Society of America 135(6). 3570-3584.
Fox, R. A. & E. Jacewicz. 2009. “Cross-dialectal variation in formant dynamics of American English vowels”, en: Journal of the Acoustical Society of America 126. 2603-2618.
García Jurado, A. & M. Arenas. 2005. La fonética del español: análisis e investigación de los sonidos del habla. Ciudad Autónoma de Buenos Aires: Quorum.
Green, J. N. 1990. “Spanish”, en B. Comrie (ed.), The World´s Major Languages, 236-259. Oxford, Nueva York: Oxford University Press.
Hillenbrand, J., L. A. Getty, M. J. Clark & K. Wheeler. 1995. “Acoustic characteristics of American English vowels”, en: Journal of the Acoustical Society of America 97. 3099–3111.
Hualde, J. I. 2014. Los sonidos del español: Spanish language edition. Cambridge: Cambridge University Press.
Jacewicz, E., R. A. Fox & J. Salmons. 2011a. “Vowel change across three age groups of speakers in three regional varieties of American English”, en: Journal of Phonetics 39. 683-693.
Jacewicz, E., R. A. Fox & J. Salmons. 2011b. “Cross-generational vowel change in American English”, en: Language Variation and Change 23. 45-86.
Jin, S.-H. & C. Liu. 2013. “The vowel inherent spectral change of vowels spoken by native and non-native speakers”, en: Journal of the Acoustical Society of America 133. EL363–EL369.
Kewley-Port, D. & Y. Zheng. 1999. “Vowel formant discrimination: Towards more ordinary listening conditions”, en: Journal of the Acoustical Society of America 106. 2945–2958.
Labov, W. 1966. The social stratification of English in New York City. Washington DC: Center for Applied Linguistics.
Labov, W. 1972. Sociolinguistic patterns. Philadelphia: University of Pennsylvania Press.
Lennes M. 2003. URL https:/a/lennes.github.io/spect/
Leung, K., A. Jongman, Y. Wang & J. Sereno. 2016. “Acoustic characteristics of clearly spoken English tense and lax vowels”, en: Journal of the Acoustical Society of America 140. 45-58.
Martínez Celdrán, E. 1995. “En torno a las vocales del español: análisis y reconocimiento”, en: Estudios de fonética experimental 7,197-218.
Martínez Celdrán, E. & A. M. Fernández Planas. 2007. Manual de fonética española. Articulaciones y sonidos del español. Barcelona: Ariel.
Nadeu, M. 2014. “Stress- and speech rate-induced vowel quality variation in Catalan and Spanish”, en: Journal of Phonetics 46. 1-22.
Nearey, T. M. & P. F. Assmann. 1986. “Modeling the role of inherent spectral change in vowel identification”, en: Journal of the Acoustical Society of America 80. 1297-1308.
Peterson, G. & H. Barney. 1952. “Control methods used in a study of the vowels”, en: Journal of the Acoustical Society of America 24. 175-184.
Quilis, A. & M. Esgueva. 1983. “Realización de los fonemas vocálicos españoles en posición fonética normal”, en: Esgueva M. & M. Cantarero (eds.) Estudios de fonética I, 137-252. Madrid: CSIC.
Romanelli, S. & A. Menegotto. 2014. Hablantes de inglés que aprenden español: modelos teóricos y estudios experimentales sobre la percepción de las vocales y el acento. 1a ed. Mar del Plata: Universidad Nacional de Mar del Plata. Disponible en: http:/a/www.else-argentina.org/libros-descarga/Hablantes%20de%20ingles%20que%20aprende%20-%20Sofia%20Romanelli,%20Andrea%20C.%20Menegotto.pdf
Romanelli, S. & A. Menegotto. 2018. “Características acústicas de las vocales tónicas y átonas del español rioplatense. Efectos del estilo de habla y del contexto consonántico”, en: Signo y Seña 33. 157-179.
Romanelli, S., A. Menegotto & R. Smyth. 2015a. “Percepción y producción de acento en alumnos angloparlantes de ELSE en la Argentina: efectos del entrenamiento y la inmersión”, en: Signo y Seña 27. 47-88.
Romanelli, S., A. Menegotto & R. Smyth. 2015b. “Stress perception: effects of training and a study abroad program for L1 English late learners of Spanish”, en: Journal of Second Language Pronunciation 1(2).181-210.
Romanelli, S., A. Menegotto & R. Smyth. 2018. “Stress-induced acoustic variation in L2 and L2 Spanish vowels”, en: Phonetica 75. 190-218.
Schwartz, G., G. Aperliński, K. Kaźmierski & J. Weckwerth. 2016. “Dynamic targets in the acquisition of L2 English vowels”, en: Research in Language 2. 181-202. DOI: 10.1515/rela-2016-0011
Schwartz, G. 2018. “Vowel VISC-osity is phonological”, en: Researchgate DOI: 10.13140/RG.2.2.24152.80644
Schwartz, G., C. Kaźmierski, J. Weckwerth, M. Jekiel & K. Malarski. 2018. “Vowel dynamics in the acquisition of L2 English – a cross-sectional and longitudinal study of L1 Polish learners”, en: Researchgate DOI: 10.13140/RG.2.2.24905.65122.
Smiljanić, R. & A. R. Bradlow. 2009. “Speaking and hearing clearly: Talker and listener factors in speaking style changes”, en: Language and Linguistics Compass 3(1). 236–264.
Strange, W., A. Weber, E. Levy, V. Shafiro, M. Hisagi & K. Nishig. 2007. “Acoustic variability within and across German, French, and American English vowels: Phonetic context effects”, en: Verb phrase syntax: a parametric study of English and Spanish. 122(2). 1111-1129.
Torreira, F. & M. Ernestus. 2011. “Realization of voiceless stops and vowels in conversational French and Spanish”, en: Laboratory Phonology 2. 331-353.
Traunmüller, H. 1990. “Analytical expressions for the tonotopic sensory scale”, en: The Journal of the Acoustical Society of America 88. 97-100.
Williams, D. & P. Escudero. 2014. “A cross-dialectal acoustic comparison of vowels in Northern and Southern British English”, en: Journal of the Acoustical Society of America 136. 2751–2761.
Zagona, K. T. 1988. Verb phrase syntax: a parametric study of English and Spanish. Dordrecht, Boston: Kluwer Academic Publishers.